
Cilium has now humbled me twice. The first time a default Pod CIDR quietly ate our firewall’s subnet and hid for 8 months before blowing up. This time was worse because the bug let us think we’d won and we high-fived and closed the ticket and went home for the weekend. Monday morning it was back sitting in production like it had never left.
”Intermittent” is a four-letter word
A customer filed a ticket reporting connection refused errors hitting internal APIs. It wasn’t a full outage but random drops scattered across services with no visible pattern. The word “intermittent” in a networking ticket means the problem depends on a variable nobody’s identified yet and it will take twice as long as you think.
Internal and external API calls were failing on and off across multiple services with no recent infra changes on our end and no new deployments. The customer’s APIs just started misbehaving one morning.
We spun up Hubble and watched the traffic and almost immediately spotted INGRESS DENIED logs where Cilium’s network policies were dropping packets. That felt like an answer because network policy denials are a well-understood problem with well-understood fixes. We added an allow-all-ingress policy to isolate whether the policy was the culprit and the INGRESS DENIED logs vanished and the service came back healthy.
But we’re not leaving an allow-all-ingress in production so we tested the other variable and restarted the failing pod and removed the policy and everything still worked.
Our theory was because Cilium assigns each pod a security identity on startup and if that identity doesn’t initialize cleanly then Cilium can misidentify the pod and start dropping traffic that should be allowed. A restart gives the pod a fresh identity handshake with the Cilium agent and the policy relaxation had just been masking the symptom while the restart was the real fix giving the pod a clean identity. We documented everything and cleaned up and went home.

A few days later after a routine deployment the exact same failures came back with the same connection refused and the same randomness. Fresh pods with fresh identities had just come up so the identity theory couldn’t explain why new pods with a clean startup were still broken.
How we got played
When we restarted the failing pod the Kubernetes scheduler placed it on a different node than before and that was pure luck. That node change happened to eliminate the condition causing failures and had nothing to do with Cilium identities or stale state because the pod had simply moved.
We didn’t realize this until later but the identity theory was a dead end. Early on we did suspect the node itself might be the problem but every other workload on that node was running perfectly. If the node was bad everything on it should have been broken and it wasn’t so we moved on.
When the problem came back after deployment we stopped trusting our theories and went straight to packet captures. We traced the full path from client pod through the NLB and back and that’s where the asymmetry showed up.
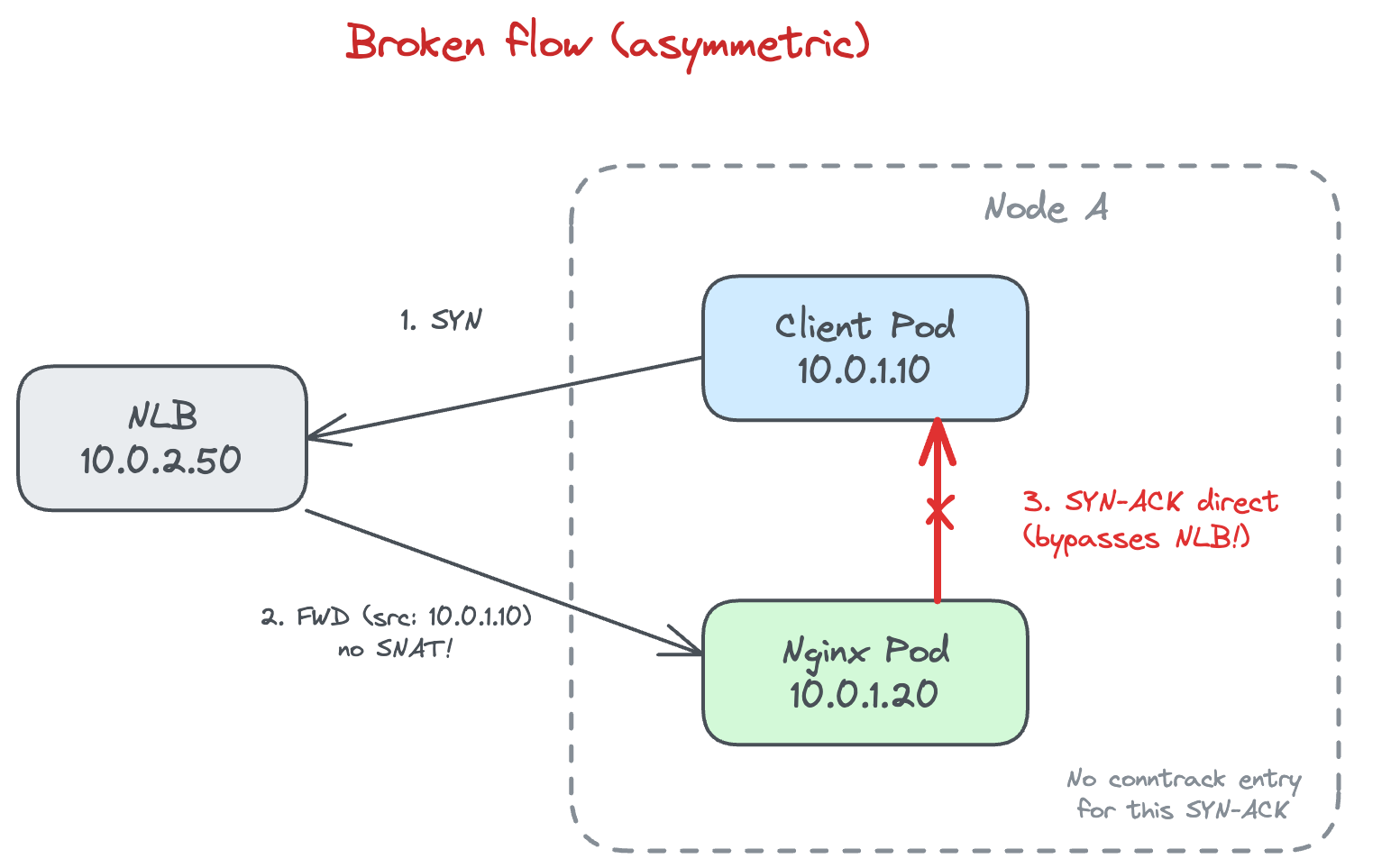
The SYN went out to the NLB but the SYN-ACK came back from a completely different source IP, specifically from the Nginx pod sitting on the same node and not from the NLB where the client had sent the original SYN. That’s when we realized the failures only happened when client and Nginx pods were co-located on the same node and the reason we’d missed it was because the node was running so many different pods that the co-location wasn’t obvious at a glance.
That pointed to hairpin routing but knowing it was hairpin didn’t explain why it failed and for that we had to understand the full packet flow.
The packet flow
Our architecture is designed so workloads can be split across multiple clusters when needed. Services call each other through public domains that resolve to an internal NLB IP so the routing works regardless of which cluster a service lives in.
In the expected flow when a client pod calls an API it resolves the domain via DNS and gets the NLB IP and sends a SYN. The NLB performs SNAT swapping the client’s pod IP with its own before forwarding to Nginx. Nginx sees traffic from the NLB IP and sends SYN-ACK back through the NLB. Symmetric path and Cilium’s conntrack is happy.
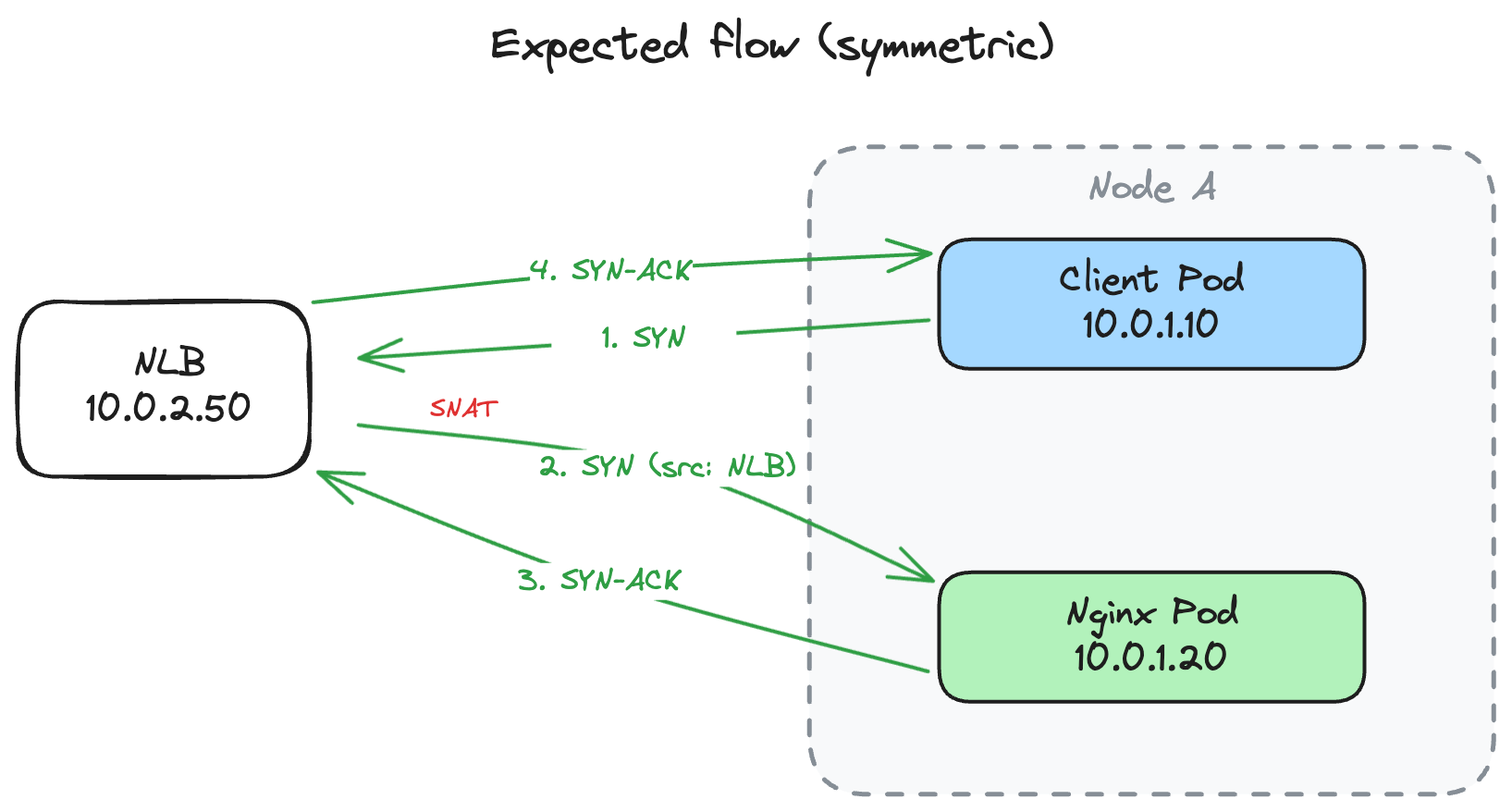
But AWS NLBs preserve the client’s source IP by default which means no SNAT. Nobody on the team had ever questioned that default because it’s the kind of setting that exists in a blind spot until it ruins your week.
Without SNAT the NLB forwards the packet with the original client pod IP intact and when the client and Nginx happen to sit on the same node the whole thing falls apart.
Cilium’s perspective (it’s not wrong)
Cilium keeps a conntrack table and when the client pod sends a SYN to 10.0.2.50 (the NLB) Cilium records:
Client Pod (10.0.1.10) -> NLB (10.0.2.50): SYN [TRACKED]It expects the SYN-ACK to come from 10.0.2.50 but Nginx is on the same node and the source IP was preserved so Nginx responds directly to the client without going back through the NLB:
Nginx Pod (10.0.1.20) -> Client Pod (10.0.1.10): SYN-ACK [???]Cilium has no conntrack entry for 10.0.1.20 because the client never sent anything to that IP and as far as Cilium can tell some random pod just tried to initiate a connection out of nowhere.
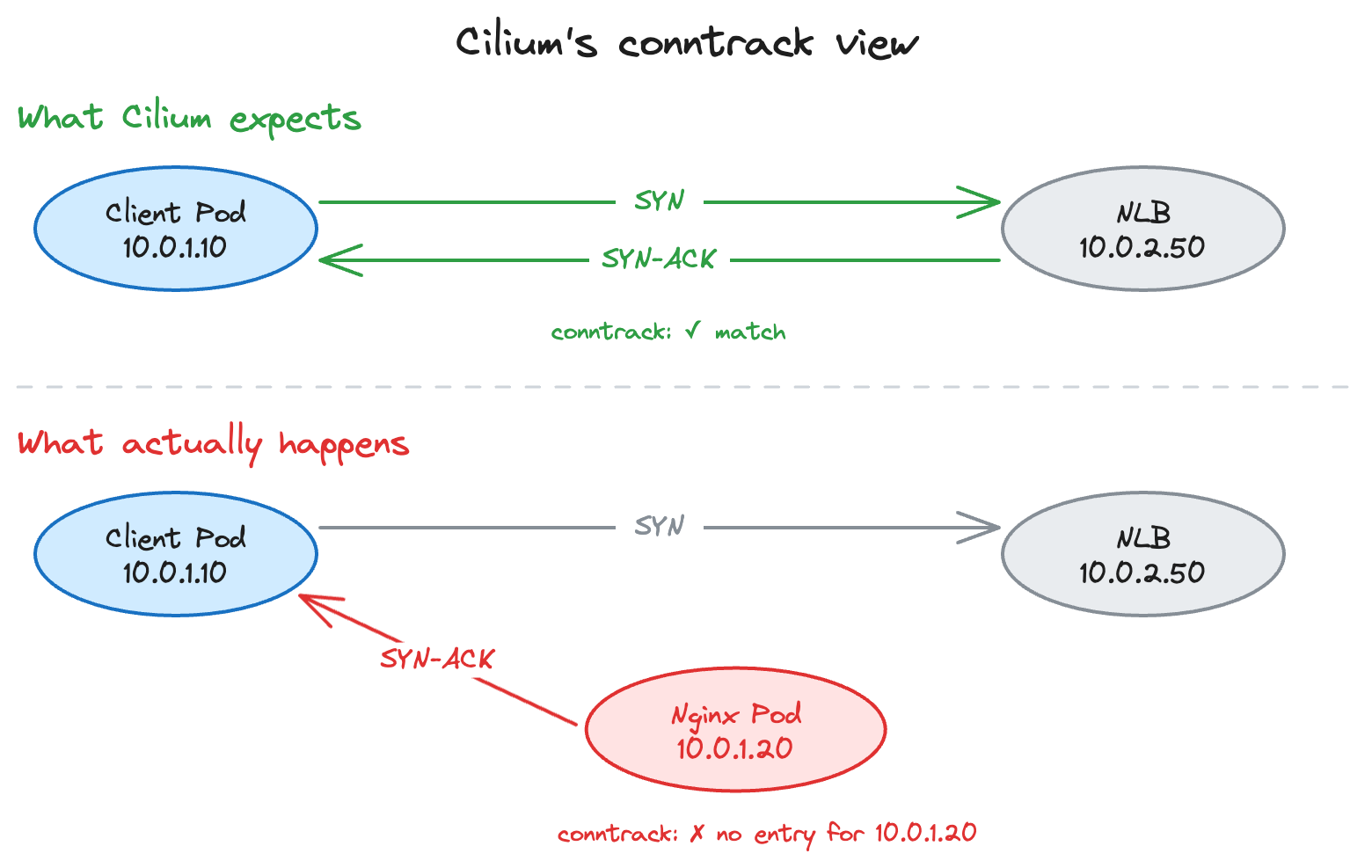
With network policies active this shows up as INGRESS DENIED and without them the stateless check passes but the stateful check still fails because Cilium can’t match the SYN-ACK to the original SYN so the TCP handshake never completes and the client hangs until it times out.
That’s why relaxing the network policy made the logs disappear without fixing anything. The denial was a symptom and the conntrack mismatch was the actual problem.
Why it was intermittent
Most of the services we host talk to each other through the mesh directly and never touch the NLB path. This internal-via-public-domain routing only exists for the handful of services that need to work across clusters and most customers never use it. On top of that the cluster had enough nodes that client and Nginx pods landing on the same node was genuinely uncommon, and since this architecture only runs behind AWS NLBs the problem didn’t exist in other environments. A rarely used routing path, an unlikely scheduling coincidence, and a single cloud provider’s default all lining up at once. It worked for a year because the odds were low, not zero.
The fix
We modified the AWS NLB service manifest for the internal ingress controller to disable client IP preservation and force the NLB to perform SNAT. One annotation in the manifest and the NLB now replaces the client pod’s source IP with its own before forwarding to Nginx. Nginx always sees traffic from the NLB and replies always go back through the NLB and you get a symmetric path regardless of where pods land.
What we changed after
We pin every load balancer setting in IaC now because cloud provider defaults are someone else’s opinion about what you probably want.
We stopped trusting clean logs as proof of a fix because logs went quiet when we relaxed the policy but the connection still failed silently at the conntrack level. Our playbooks now include TCP handshake verification instead of just log monitoring.
We map pod-to-node placement during network debugging from the start and we’re a lot more suspicious of coincidences. Two things changed at the same time and the problem disappeared but only one of them mattered and it wasn’t the one we credited.